The "Examiner" Search Engine


Motivation
One of the more efficient ways to get a good grade on a final exam is to do lots of previous exams. If this is the best way to actually learn the curriculum might be questioned of course. Most often it will depend on how the exam questions are formulated, how much they vary from year to year, the amount of creativity required, and so on. I see mainly two ideal scenarios for how final exams could be organized:
- The exams are relatively identical each year, but they are really well thought out. Previous exams are kept from the student mass in order to prevent “learning the exam” instead of “learning the course”.
- Exams vary a lot from year to year, always reformulating questions which requires deep knowledge of the course (and some creativity) in order to solve the questions being posed. This requires more work from the faculty, but previous exams need not be secret.
Only one of the scenarios are feasible though as you will never be able to keep all previous exams from circulating among the student mass. The moment a single student get their hands on a previous exam they have a tremendous competitive advantage and the system fails instantly; we have a case of the tragedy of the commons. I’ve had both experiences with courses having the same exam each year, incentivizing “learning the exam” instead of the actual curriculum, and with courses where previous exams where kept from the students, giving a huge advantage to the students that got their hands on previous exams from other students.
The only real choice here is to opt for option 2, transparently publishing all previous exams as part of a centralized archive of some sorts. As a direct consequence you put all students on an equal footing, no matter the social network or technical know-how required to get access to previous exams. In practice, most courses at NTNU actually take this approach, but perhaps it can be improved upon? That is what I aimed to do with Project Examiner, a search engine for old NTNU exams. And while I’m at it, perhaps add some additional tailor-made improvements on top? The following design goals were identified from the outset:
- Single source of truth: All exams, no matter the faculty, should be available from one single website.
- Link integrity: No links should return a
4XXresponse code. - Search functionality: Quickly find what you are looking for with an auto-completing search box.
- Filter functionality: The ability to filter the exams based on keyword-matching. Perhaps you want to find all exams which contains the words “Laplace Approximation” or “KNN”?
- Easy navigation: All exams for a given course, including solutions, in a single table.
- Equal access: All web-users should be able to access the site.
- Legality: The University is the final copyright holder for all exams, so we should redirect to other websites.
Some of the existing solutions out there satisfy some of these criteria, but none all of them at the same time.
Overall idea
The overall design of the implementation should be relatively straight forward, this is a highly specialized form of a search engine, and we should be able to make a lot of simplifying assumptions along the way. In order to achieve our goals, we must implement the following subsystems:
- Crawler: A crawler that is able to traverse existing websites which serve old NTNU exams, fetching all relevant URLs.
- Cacher: A downloader which fetches and permanently stores exam PDFs for classification purposes.
- Converter: A way to convert PDF files to raw text.
- Classifier: A way to classify all the relevant metadata for a given PDF, such as the related course, year, season, and so on.
- Search engine: A way to find the relevant exams from a single search form.
- Presentation: Presenting the resulting search results in a suitable form.
- Human verification: A way for humans to verify or correct the results of classification algorithm.
Ignoring the front-end aspects for now, the control flow will look something like this:
graph TD;
url1(fa:fa-cloud<br>Mathematics<br>Department)
click url1 "https://wiki.math.ntnu.no/emner"
url2(fa:fa-cloud<br>Physics<br>Department)
click url2 "https://www.ntnu.no/fysikk/eksamen"
url3(fa:fa-cloud<br>External<br>Student Resources)
click url3 "https://dvikan.no/gamle-ntnu-eksamener/"
crawler[fa:fa-spider Crawler]
downloader[fa:fa-database Downloader and Hasher]
converter[fa:fa-file-pdf Pdf-to-Text Conversion]
classifier{fa:fa-search Content Classification}
url1 -->|HTML| crawler
url2 -->|HTML| crawler
url3 -->|HTML| crawler
crawler -->|URL| downloader
downloader -->|PDF| converter
converter -->|Text| classifier
classifier --> Exam?
classifier --> Solutions?
classifier --> Course
classifier --> Semester
classifier --> Year
Most of the difficult problems will be faced in the back-end in the control flow above, otherwise it will be a relatively simple CRUD app. We will implement this as a webapp using the Django python web framework. That way we will be able to utilize the wide array of packages available in the python ecosystem, simplifying some the task ahead.
Implementation
We will now try to implement all these components while trying to keep them as decoupled as possible.
Crawler
We start by implementing the crawler, focusing on websites which we know contain a lot of of old NTNU exams, namely:
- All the mathematical course pages hosted by the Mathematics Department.
- The physics exam archive hosted by the Physics Department.
- Various exams hosted by the NTNU alumni Dag Vikan.
The crawling strategy will differ somewhat between each source, so we will pull the common logic into a BaseCrawler abstract base class and then subclass it for each additional crawl source we implement.
Here is the simplified code for the Mathematics Department crawler, where I have removed exception handling and imports, and glossed over some other details to keep it more concise:
class MathematicalSciencesCourseCrawler(BaseCrawler):
WIKI_URL = 'https://wiki.math.ntnu.no/'
def __init__(self, code: str) -> None:
self.code = code
@property
def homepage_url(self) -> str:
return self.WIKI_URL + self.code
def exams_pages(self) -> List[str]:
"""Return all exam archives for given course."""
response = requests.get(self.homepage_url, timeout=2)
years = soup.find_all(
'a',
text=re.compile(r'^.*(?:20[0-2]\d|199\d).*$'),
href=True,
)
for year in years:
...
def pdf_urls(self) -> List[str]:
"""Return all PDF URLs for given HTML document."""
result = set()
for exams_url in self.exams_pages():
links = bs(response.content, 'html.parser').find_all('a')
for link in links:
if link.get('href') and link.get('href').endswith('.pdf'):
result.add(urljoin(self.WIKI_URL, link.get('href')))
return resultIn order to make the later classification easier, we will try to restrict the crawler to only find PDF anchor tags which are likely to point to exams. Otherwise we have to distinguish between exams and other course material, such as syllabi, lecture plans, and so on. In this crawler this means trying to navigate to a subpage which contains the word “Exam” or something similar before retrieving all PDF anchor tags. See the source code for more details.
Note
Possible future improvement: Instead of using requests and BeatifulSoup4 for scraping and parsing, Scrapy might be a better fit as it is intended exactly for this kind of scraping.
Downloader
Now that all URLs of interest have been persisted to the database, we can start downloading these PDFs. Here are the processing steps:
graph LR; URL(fa:fa-link URLs) Downloader[fa:fa-file-download Downloader] Hasher[fa:fa-percent SHA1-hasher] Media[fa:fa-database Media Storage] URL --> Downloader Downloader --> Hasher Hasher --> Media
For each URL we try to download the PDF using requests.
If the URL returns a failure HTTP code, we persist this as PdfUrl.has_content = False so we don’t have to bother with the URL in the future.
Otherwise we persist the PDF file to Django’s media storage along with a Pdf model object which stores the filename (parsed from the URL).
Tip
We calculate the SHA1-hash of the PDF file and enforce uniqueness on this hash in the database. That way we prevent ending up with lots of duplicate PDF which are caused by different URLs serving the same PDF document. Keep in mind that we should hash the PDF files in chunks in order to preserve memory and increase speed, as we can read the binary data as it comes in over the wire.
Here is how the PdfUrl.backup_file() ends up looking in practice:
class PdfUrl(models.Model):
...
def backup_file(self) -> bool:
"""
Download and backup file from url, and save to self.file_backup.
:return: True if the PDF backup is a new unique backup, else False.
"""
try:
response = requests.get(self.url, stream=True, allow_redirects=True)
except ConnectionError:
self.dead_link = True
self.save()
return
if not response.ok:
self.dead_link = True
self.save()
return
sha1_hasher = hashlib.sha1()
temp_file = NamedTemporaryFile()
for chunk in response.iter_content(chunk_size=1024):
if chunk:
temp_file.write(chunk)
sha1_hasher.update(chunk)
content_file = File(temp_file)
sha1_hash = sha1_hasher.hexdigest()
try:
file_backup = Pdf.objects.get(sha1_hash=sha1_hash)
new = False
except Pdf.DoesNotExist:
new = True
file_backup = Pdf(sha1_hash=sha1_hash)
file_backup.file.save(name=sha1_hash + '.pdf', content=content_file)
file_backup.save()
self.scraped_pdf = file_backup
self.dead_link = False
self.save()
return newPDF-to-Text Conversion
Now that the PDFs have been persisted to disk, we should be able to convert the PDF documents to raw text, which will be used as one of the inputs to the classification algorithm later on. This proved to be much more difficult than first anticipated, as PDFs do not require text to be indexable. In practice there are two types of PDFs (at least of interest to us):
- PDF/A files which are suitable for long-term preservation and archiving, often with indexable text.
- Scanned PDFs which might consists of single page images resulting from an exam being scanned to digital format.
The first is relatively easy to handle for our purposes, we can simply use pdf2text utility from the Poppler PDF rendering library. We will use a python wrapper for the utility. It is as easy as:
import pdftotext
with open(pdf_path, 'rb') as file:
try:
pdf = pdftotext.PDF(file)
except pdftotext.Error:
# Handle exception
...
pdf_pages = [page for page in pdf]What proved to be difficult though was the except pdftotext.Error: part.
This is mostly caused by trying to parse the text from scanned PDFs which are basically images in document format.
We are now forced to do some sort of Optical Character Recognition (OCR) in order to convert these “images” to raw text.
Tesseract OCR is suitable for this task:
This package contains an OCR engine - libtesseract and a command line program - tesseract. Tesseract 4 adds a new neural net (LSTM) based OCR engine which is focused on line recognition
Tesseract has unicode (UTF-8) support, and can recognize more than 100 languages “out of the box”.
Tesseract supports various output formats: plain text, hOCR (HTML), PDF, invisible-text-only PDF, TSV.
Warning
Tesseract OCR only supports machine written text, but as all exams and most solution sets are typeset in LaTeX this is not a too big drawback for our purposes at the moment.
It might still be preferable to use Google Cloud Vision OCR for instance, which also supports handwriting detection.
The pricing structure is set to 1.50 USD for every thousand page, which shouldn't be too cost prohibitive.
Luck has it that this package, of which work started in in 1985, received a major v4.0 update in October of 2018 with lots of improvements.
The newest version of the Tesseract OCR engine uses neural networks under the hood, and several pretrained NNs are available for download.
These networks can be combined, and we will use the eng (English), nor (Norwegian), and equ (equation) networks as this covers 99% of all the exams at NTNU.
I have had mixed success with the equ trained data, and have also tried the grc (Greek) trained data to recognize mathematical symbols which failed miserably.
These types of symbols are only nice-to-haves anyway, so we won’t bother too much with them as they are not critical for the classification algorithm.
Note
Possible future improvement: Tesseract OCR allows you to train your own neural nets. We could therefore train a net based on all the remaining PDF/A files, using the `pdftotext` results as ground truth. This might result in better text conversion as it becomes tailor made for NTNU formatted exam PDFs.
Instead of subshelling out to the Tesseract CLI we will use the tesserocr python wrapper instead.
There is still one minor fact to be dealt with though before we can use invoke tesserocr, namely that Tesseract OCR only accepts “proper” image formats as input, .png and .tiff for instance.
We will opt for the latter, and we therefore need to find a way to convert multi-page PDFs to multiple TIFF files, on for each page.
I started experimenting with ImageMagick and its python wrapper Wand, but it had troubles with multi-page documents and layered PDFs which needed to be flattened.
The pythonic API wasn’t worth the hassle and I ended up using Ghostscript instead.
There are a lot of command flags to read up on, but this blogpost was of tremendous help.
It can be done by subshelling out to the ubiquitous CLI interface:
def _tiff_directory() -> TemporaryDirectory:
"""
Return Path object to directory containing TIFF files.
One TIFF image is created for each page in the PDF, and are sorted in
alphabetical order wrt. page number of the original PDF. This is so
because tesserocr does not support multi-page TIFFs at the date of this
implementation.
NB! The TIFF files are contained in a tempfile.TemporaryDirectory, and
all files are deleted when this object goes out of scope.
"""
_tmp_tiff_directory = TemporaryDirectory()
# For choice of parameters, see:
# https://mazira.com/blog/optimal-image-conversion-settings-tesseract-ocr
subprocess.run([
# Using GhostScript for PDF -> TIFF conversion
'gs',
# Prevent non-neccessary output
'-q',
'-dQUIET',
# Disable prompt and pause after each page
'-dNOPAUSE',
# Convert to TIFF with 16-bit colors
# https://ghostscript.com/doc/9.21/Devices.htm#TIFF
'-sDEVICE=tiff48nc',
# Split into one TIFF file for each page in the PDF
f'-sOutputFile={_tmp_tiff_directory.name}/%04d.tif',
# Use 300 DPI
'-r300',
# Interpolate upscaled documents
'-dINTERPOLATE',
# Use 8 threads for faster performance
'-dNumRenderingThreads=8',
# Prevent unwanted file writing
'-dSAFER',
# PDF to convert
str(self.path),
# The following block contains postcript code
'-c',
# Allocate 30MB extra memory for speed increase
'30000000',
'setvmthreshold',
# Quit the ghostscript prompt when done
'quit',
'-f',
])
return _tmp_tiff_directoryWe can finally get cracking with the OCR, using these TIFF files as input.
The final method looks something like this (NB! It is part of a bigger PdfReader class, see full source code for details):
class PdfReader:
...
def read_text(
self,
*,
allow_ocr: bool,
force_ocr: bool = False,
) -> Optional[str]:
"""
Return text content of PDF.
:param allow_ocr: If text cant be extracted from PDF directly, since
it does not contain text metadata, text will be extracted by OCR if
True. This is much slower, approximately ~5s per page.
:param force_ocr: If True, OCR will be used instead of pdftotext in
all cases.
:return: String of PDF text content, pages seperated with pagebreaks.
"""
if force_ocr:
return self.ocr_text()
with open(self.path, 'rb') as file:
try:
pdf = pdftotext.PDF(file)
except pdftotext.Error:
if not (allow_ocr and OCR_ENABLED):
raise PdfReaderException(
'Can not read text from PDF and OCR is disabled!'
)
else:
return self.ocr_text()
self.pages = [page for page in pdf]
self.page_confidences = [None] * len(self.pages)
self.mean_confidence = None
text = '\f'.join(self.pages)
if len(text.replace('\f', ' ').strip()) > 1:
return text
elif allow_ocr and OCR_ENABLED:
return self.ocr_text()
else:
return NoneTip
If you encounter the following crash when you import tesserocr:
!strcmp(locale, "C"):Error:Assert failed:in file baseapi.cpp, line 209
Set the following environment variables before invoking the python interpreter again:
export LC_ALL=C PYTHONIOENCODING="UTF-8"
The bug has been reported but no fix has been published as of this writing.
As you can see, we can retrieve Tesseract’s confidence for each word, something we will persist to the model object PdfPage.
The final text conversion pipeline ends up looking like this:
graph LR;
pdf[fa:fa-file-pdf PDF]
identifier{PDF type identifier}
pdf --> identifier
indexable[Pdf2Text]
scanned1[GhostScript]
scanned2[Tesseract v4.0]
identifier -->|PDF/A| indexable
identifier -->|Scanned PDF| scanned1
scanned1 -->|TIFFs| scanned2
pdfpage[fa:fa-database PdfPage]
scanned2 -->|raw text| pdfpage
indexable -->|raw text| pdfpage
Classifier
Now that we have lots of PDF URLs and their respective PDF files in local storage, we need to classify them. Here is the relevant metadata we would like to identify:
course_code- Unique identifier for course, i.e. “TMA4100”.language- One of: Bokmål, Nynorks, English.year- Year of examination.season- One of: spring, autumn, summer (so called “continuation” exam for previously failed students).solutions- True if the documents includes the problem solutions.
What information is available for us to actually perform this classification?
- Raw text content of the PDFs - This is the ideal alternative, but some PDF documents are poorly converted to raw text.
- The URL(s) hosting those PDFs - Several conflicting URLs that are not necessarily written for human reading, but most of them contain valuable information anyhow.
- The surrounding HTML context from which the URLs where scraped - Made for human reading, but inconsistent use of tables, lists and other semantic structures makes it difficult to infer the metadata in a generic way.
We are opting for a hybrid approach here, parsing/classifying all the URLs and combining the results with the results from parsing/classifying the PDF text contents.
Returning None when we are unsure and giving precedence to the PDF text parser might give decent results.
URL classifier
This sort of algorithm is highly suited for a test-driven approach. Let’s specify some URLs and what the resulting metadata should be inferred as:
ExamURLs = (
ExamURL(
url='http://www.math.ntnu.no/emner/TMA4130/2013h/oldExams/eksamen-bok_2006v.pdf',
code='TMA4130',
year=2006,
season=Season.SPRING,
solutions=False,
language=Language.BOKMAL,
probably_exam=True,
),
ExamURL(
url='http://www.math.ntnu.no/emner/TMA4130/2013h/oldExams/lf-en_2006v.pdf',
code='TMA4130',
year=2006,
season=Season.SPRING,
solutions=True,
language=Language.ENGLISH,
probably_exam=True,
),
...
)We can use this tuple as a parametrized fixture in the following way:
class TestExamURLParser:
@pytest.mark.parametrize('exam', ExamURLs)
def test_year_parsing(self, exam):
url_parser = ExamURLParser(url=exam.url)
assert url_parser.year == exam.year
@pytest.mark.parametrize('exam', ExamURLs)
def test_course_code_parsing(self, exam):
url_parser = ExamURLParser(url=exam.url)
assert url_parser.code == exam.code
# And so on...Now we can get going with actually implementing ExamURLParser.
Let’s look at the following URL encountered in the wild:
http://www.math.ntnu.no/emner/TMA4130/2013h/oldExams/eksamen-bok_2006v.pdf
There is a lot of information to be gleaned from this URL, parsing from left to right we have:
TMA4130→ Matematikk 4N2013h→ Autumn (høst) semester of 2013oldExams→ Exameksamen→ Exambok→ Norwegian Bokmål2006v→ Spring (vår) semester of 2006
We should lend more weight to keyword matches at the end of the string, as they can be considered more specific to the file. I have opted for the relatively naive approach of pattern matching using regular expressions. The development workflow goes something like this:
- Rewrite the pattern matcher in order to succeed at the new test case.
- Make sure that no previous test cases end up failing as a consequence.
- Print out the classification results for all (non-tested) URLs in the database and add failing URLs to
ExamURLs. - Rinse and repeat.
This process has lead me to having 54 test cases, all of which are succeeding.
There is still quite a lot of work to be done, but the end result is usable as a minimal viable product.
I won’t bore you with the details of the final implementation, rest assured that it is regular expression after regular expression matching all kinds of edge cases.
If that still doesn’t scare you away, you can read the source code for the examiner.parsers module here.
Text content
We can now apply the same test approach for the PDF text classifier:
ExamPDFs = (
ExamPDF(
pages=[
"""
NTNU TMA4115 Matematikk 3
Institutt for matematiske fag
eksamen 11.08.05
Løsningsforslag
Eksamenssettet har 12 punkter.
""",
],
course_codes=['TMA4115'],
year=2005,
season=Season.CONTINUATION,
solutions=True,
language=Language.BOKMAL,
content_type=DocumentInfo.EXAM,
),
...
)With respective tests in the same manner. The only difference stems from my realization that the same exam might be given for several different courses. Another complication for the classifier and the accompanying data model. Also, the myriad of different ways to format dates has been a constant pain, from what I found, the available dateparsers do not handle international formats and edge cases well, so I had to roll my own implementation. Other than that, this classifier was much easier to implement for non-garbage text, and 11 test cases seemed to be enough in order to test most edge cases.
Note
Possible future improvement:
The Physics Department's official exam archive uses a really consistent and well-structured URL pattern, so much so that I opted to bypass the generic URL parser all-together and write a custom one instead.
The resulting PDF classification algorithm for these PDFs must therefore have a negligible missclassification rate, and could possibly be used as training set for a more sophisticated classification model.
Pulling it all together
Now that all the individual components have been implemented, we should pull them together.
The most practical way is to create a separate django-admin command for the examiner app.
That way we can run the entire pipeline on a schedule using a cronjob, and potentially rerun parts of the pipeline if we have made improvements.
The source code can be read here and we can invoke the different subsystems with python manage.py examiner [options].
Here is an abbreviated version of the CLI documentation for the command:
$ python manage.py examiner --help
usage: manage.py examiner [--crawl] [--backup] [--classify] [--test]
[--gui] [--retry] [course_code]
Crawl sources for exam PDFs.
positional arguments:
course_code Restrict command to only one course.
optional arguments:
--crawl Crawl PDF URLs from the internet.
--backup Backup PDF files from the internet.
--classify Read and classify content of PDF backups.
--test Run examiner interactive tests.
--gui If GUI tools can be invoked by the command.
--retry Retry earlier failed attempts
Infrastructure
Since the entire OCR pipeline requires a whole bunch of system dependencies, docker might alleviate some pains in operating this Django app.
Using the linuxserver/letsencrypt image for nginx we can easily support HTTPS, which we want to.
Besides that we need postgres and django.
The resulting docker-compose.yml file can be found here.
The Dockerfile for the django container required some more acrobatics though.
Since the app was production ready before Alpine Linux v3.9.0 was released with Tesseract v4.0 in the mainline repository, I had to use a separate Alpine Tesseract 4 package builder in order to pull over the binary from a test repository.
That and all other system dependencies have been specified in the following Dockerfile.
With all this in place, setting the system into production is one single docker build away.
The final system runs as a DigitalOcean Docker droplet for easy (re-)deployment.
Front-end
This is where I leave this article off (for now at least). Future content to come:
- Searching for a course with auto-completion, using django-autocomplete-light.
- Presenting the relatively dense information set in form of a easy-to-read HTML table.
- Filtering down the exams in real time based on keyword matching, using the Filterable jQuery widget.
- Ability to verify and/or correct the resulting classifications as a trusted human, using django crispy-forms and django-dataporten.
In the meantime you can try the final product here or take a look at some of the screenshots in the gallery below.
Front-end screenshot gallery
Frontpage
Keeping it simple (ala Google) the user is presented with nothing more than a search box.
Smart autocompletion
When the user starts entering text, we populate the dropdown list in real time based on fuzzy matches against:
- Course code
- Course name
- Course nicknames (if entered into the database)

Loading animation
Loading animation while database queries run after having entered the course code.
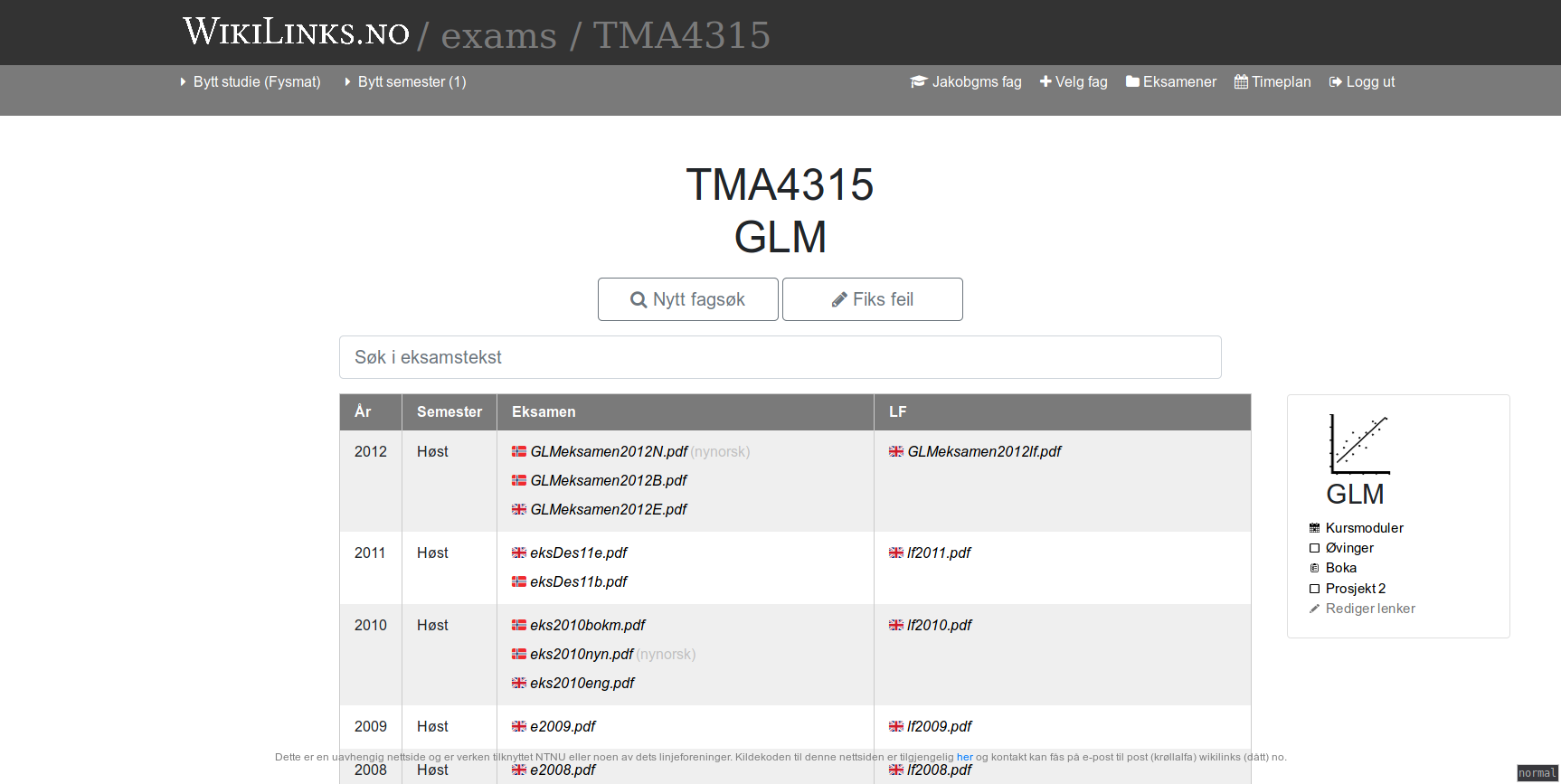
Tableview
All the exams are sorted in inverse chronological order, split by solution, and grouped by language.
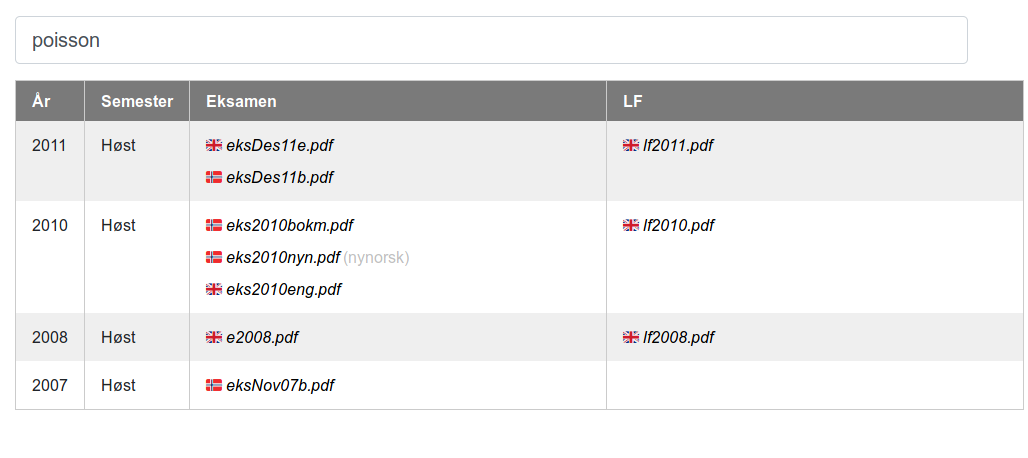
Real-time keyword filtering
The user is able to filter down the exam list in real-time, here matching on the word “poisson”.
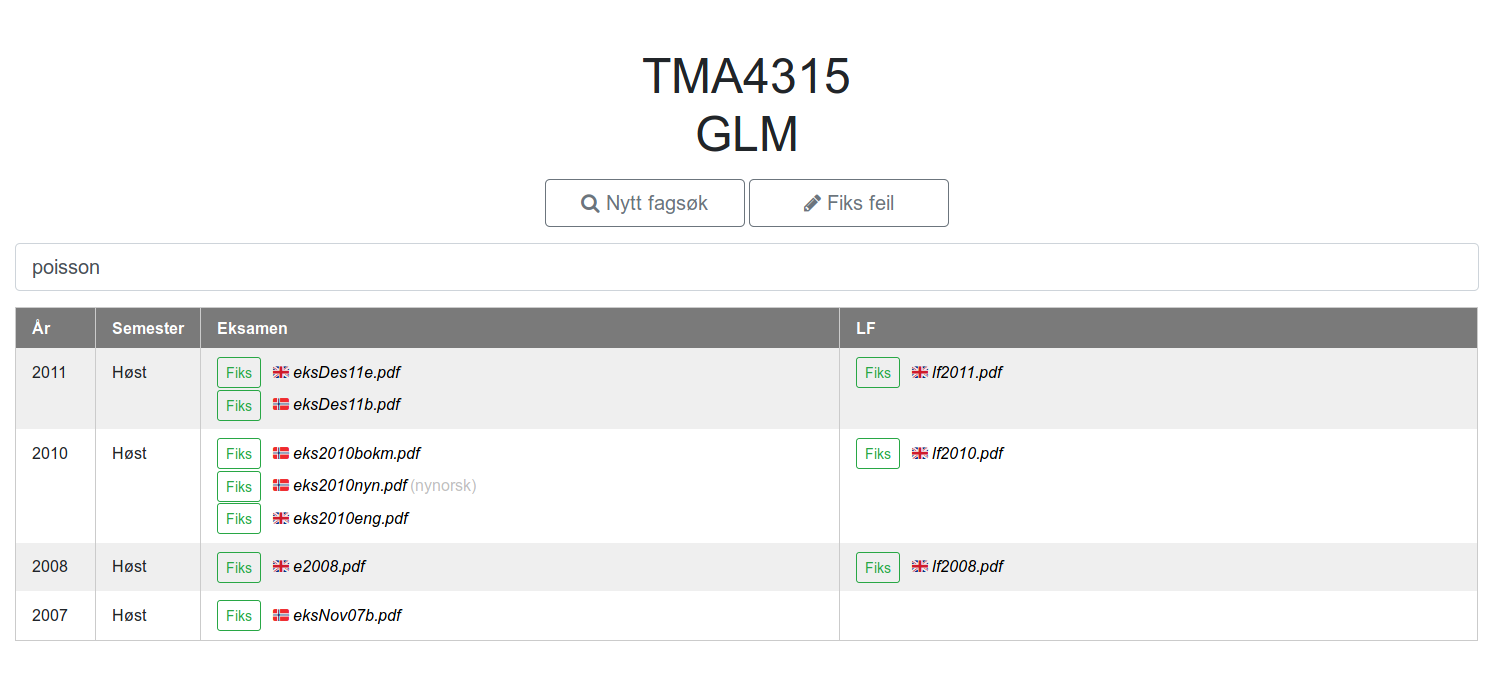
“Edit-selector”
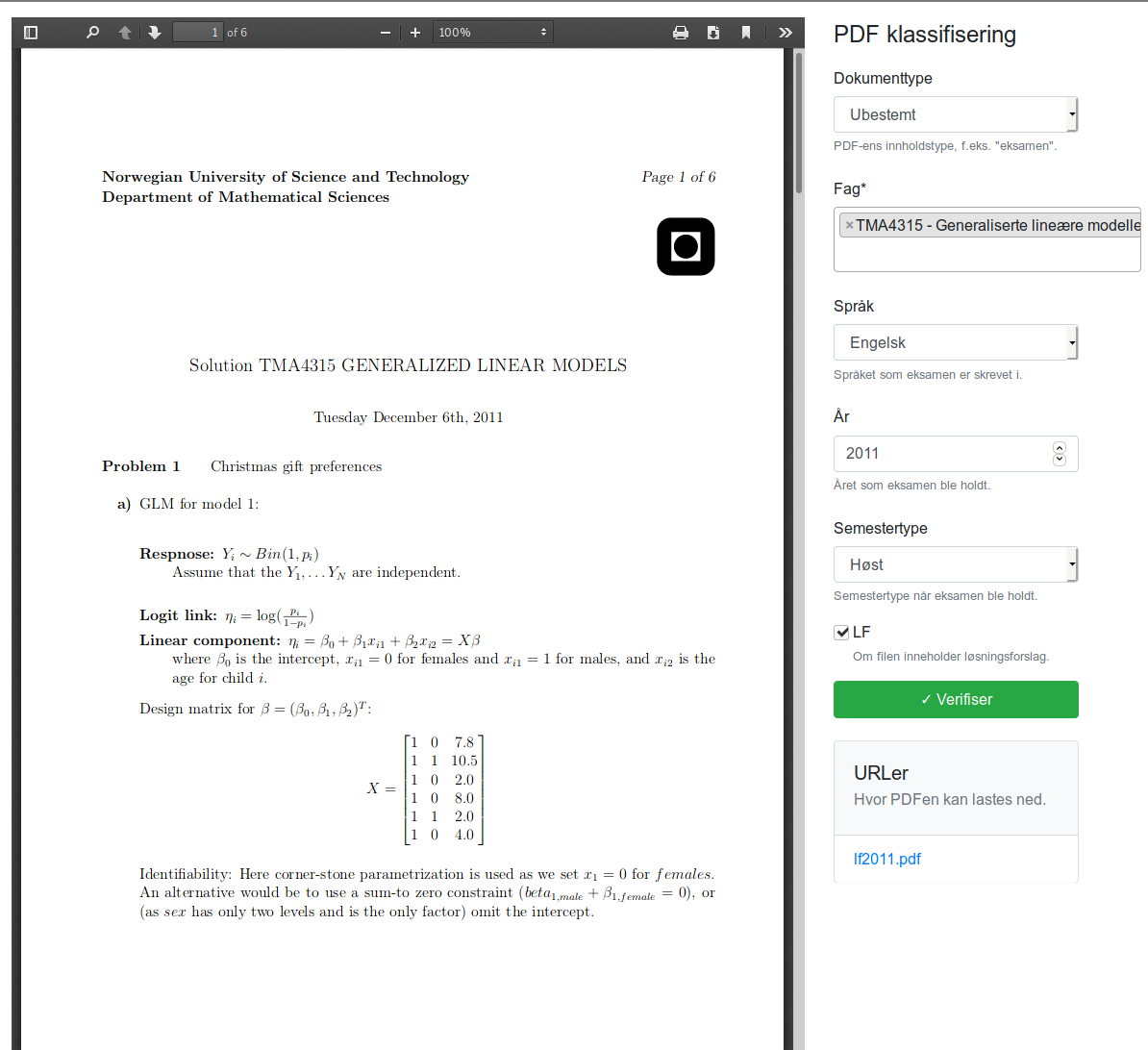
If the user detects an error they can enter the “edit-selector” in order to select a link for review. The intention is to hide the clutter that this would otherwise have introduced if the buttons were shown by default.
“Edit-mode”
In “edit-mode” the user can review a pre-populated metadata form for the PDF based on the classification algorithm. If the user saves the result, no further changes will be made by the classification algorithm in the future.